

Deploying ML Models to Production: A Web Builder's Practical Guide
Deploying ML models to production is where most teams hit a wall they didn't see coming. Your model performs beautifully in a notebook, then the real world breaks it. This guide covers the architecture, patterns, and monitoring strategies that keep models serving reliable predictions, and how to avoid the failure modes that nobody warns you about.
Why Deploying ML Models Fails for Most Teams
Most ML deployment failures come down to the same cluster of problems: no visibility after launch, no versioning discipline, and infrastructure that was never designed for the load patterns of a real product. Teams ship the model and assume the hard work is done. It isn't.
Your trained model works perfectly in a Jupyter notebook. Then it hits production and something breaks. Maybe it's data drift: the input distributions in the real world don't match what you trained on. Maybe it's a latency spike because nobody profiled the inference time under concurrent load. Maybe it's an unhandled edge case that sends the whole service into an error loop.
What makes this worse is that you usually don't know. There's no alert, no dashboard, no on-call rotation. Feature importance silently shifts. Predictions decay. Customers start noticing before your engineering team does.
Versioning is another common disaster. Which model is actually running in production right now? Did the latest push deploy successfully? If inference suddenly gets slow or wrong, can you roll back in under five minutes? If you can't answer all three questions instantly, you have a problem.
Infrastructure costs are the slow bleed. Teams that didn't architect for async batch processing, intelligent caching, or request prioritization watch their compute bill climb with no corresponding improvement in product quality. And when the ML service goes down, the entire product often stops with it. That's not a monitoring problem; it's an architecture problem.
Why Production Deployment Is Fundamentally Different from Training
Deploying ML models to production requires a completely different mindset from model training. Training is an offline, iterative process. Serving is a 24/7, latency-sensitive, fault-prone operation that handles messy real-world data at scale.
Training happens once, or maybe quarterly. Serving happens millions of times. You stop optimizing purely for accuracy and start optimizing for latency, throughput, and cost. Those are different objectives, and they require different engineering decisions.
The Sculley et al. research from Google on hidden technical debt in machine learning systems made this case clearly: the actual model code is a tiny fraction of the total engineering surface area. The surrounding infrastructure, data pipelines, serving layers, and monitoring systems account for the majority of the work. Teams that treat the model as the product, rather than one component of a production system, consistently underestimate what they're actually building.
Your training data was curated and cleaned by someone who knew what the model needed. Production data arrives raw, incomplete, and sometimes adversarial. Users upload files in unexpected formats. They send null values, extreme outliers, and inputs that fall completely outside your training distribution. Your model has never seen any of it.
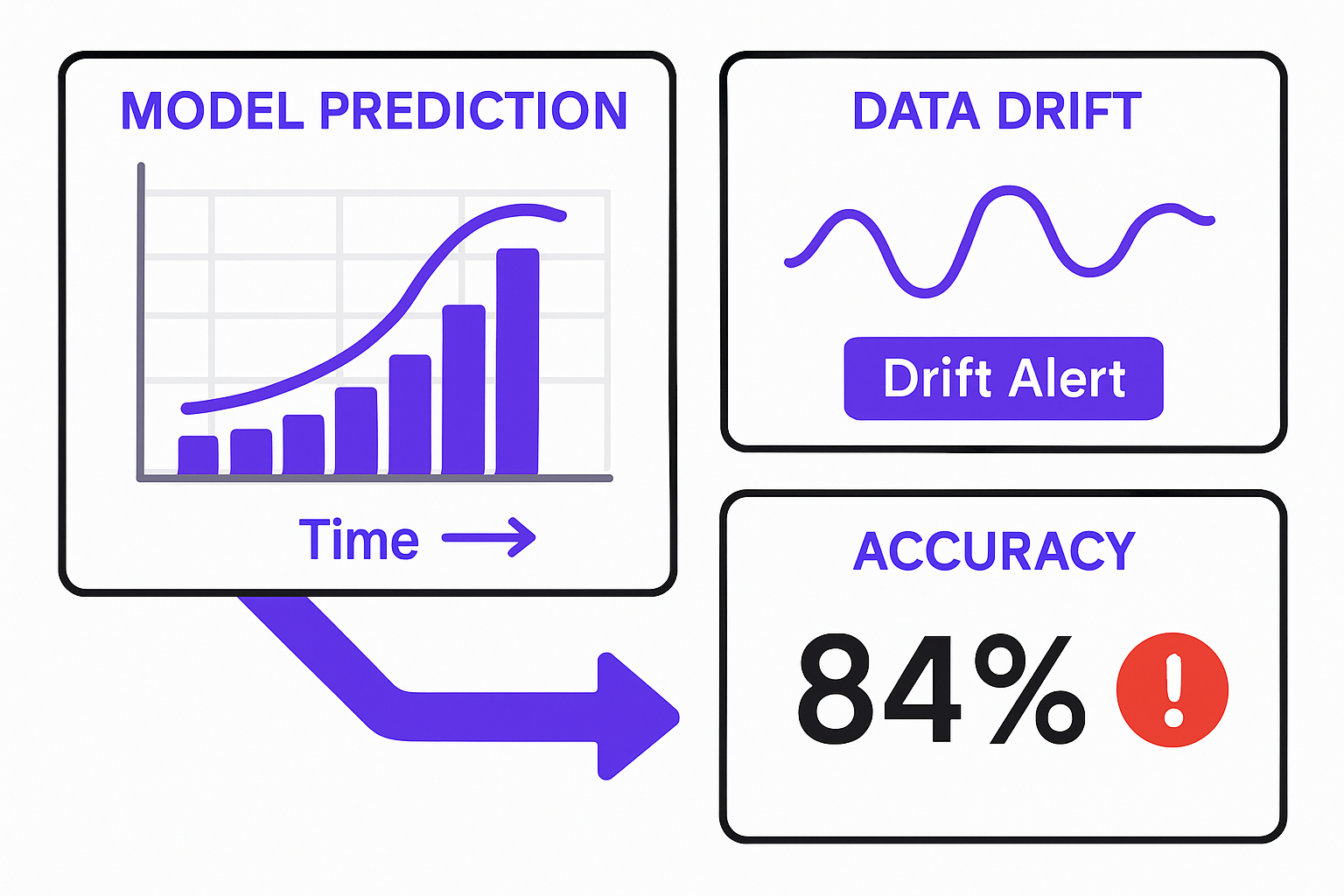
Then there's model decay. Distributions shift over time. User behavior changes. The product evolves. A model that was accurate on your 2023 training data will quietly degrade through 2024 and 2025 unless you're measuring it. Papers With Code MLOps Benchmarks track this kind of drift across production deployments, and the pattern is consistent: unmonitored models degrade faster than teams expect.
You also need rollback capability, A/B testing, canary deployments, and fallback logic. These aren't nice-to-haves. They're the difference between a research artifact and a production system.
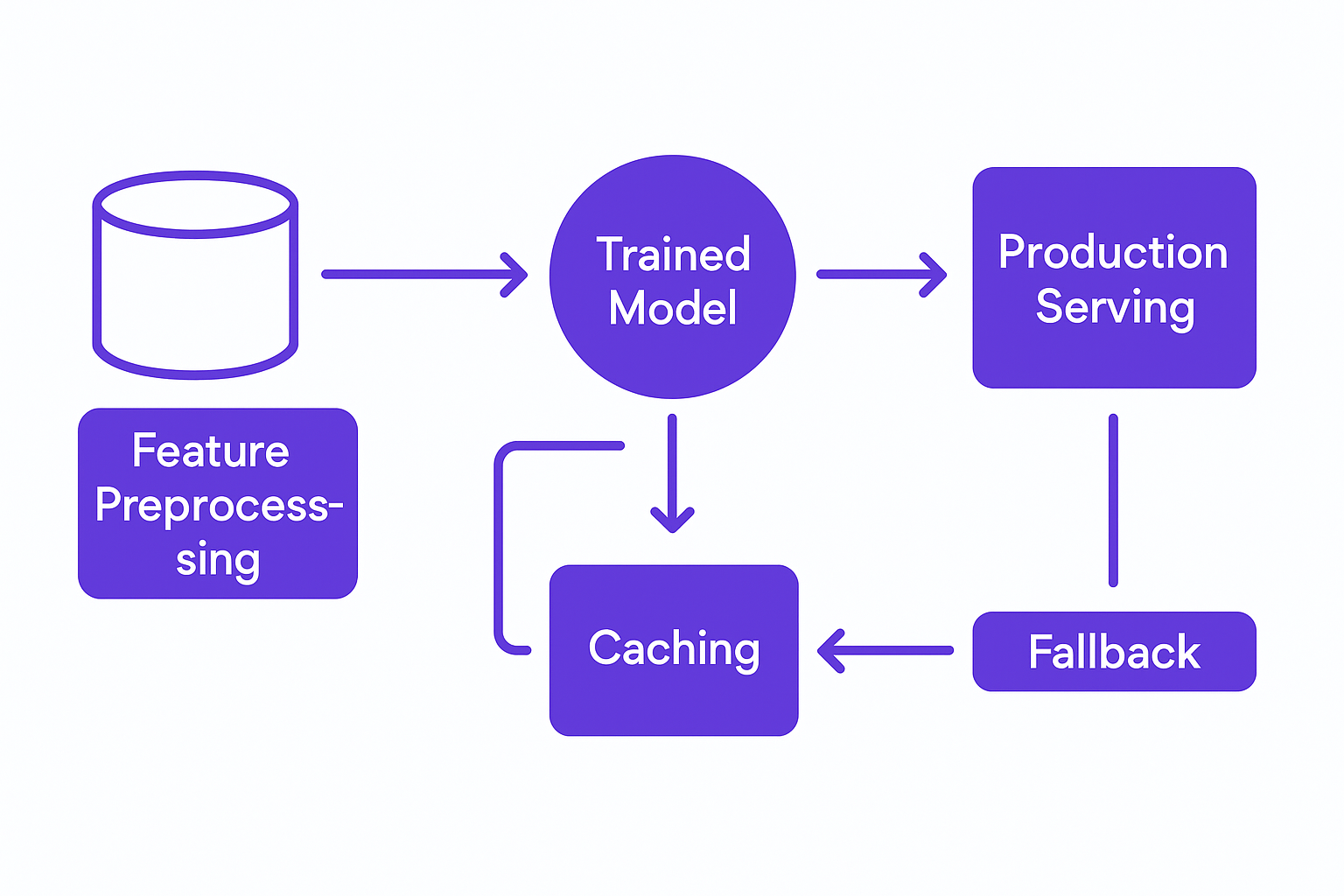
The Production ML Architecture That Works
A production-ready ML deployment rests on six components, each with a specific job. Skip any of them and you're building on sand.
Feature Store
Serve pre-computed, versioned features at inference time instead of recomputing them on every request. A feature store cuts inference latency significantly and, more importantly, keeps your training and serving pipelines in sync. Databricks Feature Store Best Practices document the specific versioning and consistency patterns that prevent training-serving skew, one of the most common and hardest-to-debug production failure modes.
Model Registry
Version every model. Tag every deployment. Store metadata: accuracy metrics, drift scores, training date, dataset version. When something goes wrong in production, you need to roll back in seconds, not hours. Without a registry, you're guessing.
Inference Layer
Run lightweight prediction servers behind a load balancer. FastAPI, TensorFlow Serving, and Ray Serve are all solid choices depending on your stack. For predictions that don't need to be synchronous, put them behind an async queue. Don't make users wait for something that can run in the background.
Monitoring and Observability
Track prediction latency, error rates, model confidence distributions, and data drift. Set alerts on degradation, not just outages. The system should tell you when performance is declining, before it becomes a customer-facing problem.
Fallback and Graceful Degradation
If your ML service times out or returns an error, the product should not go down with it. Fail to a rule-based default, return a cached prediction, or queue the request for later processing. This is non-negotiable in any production deployment.
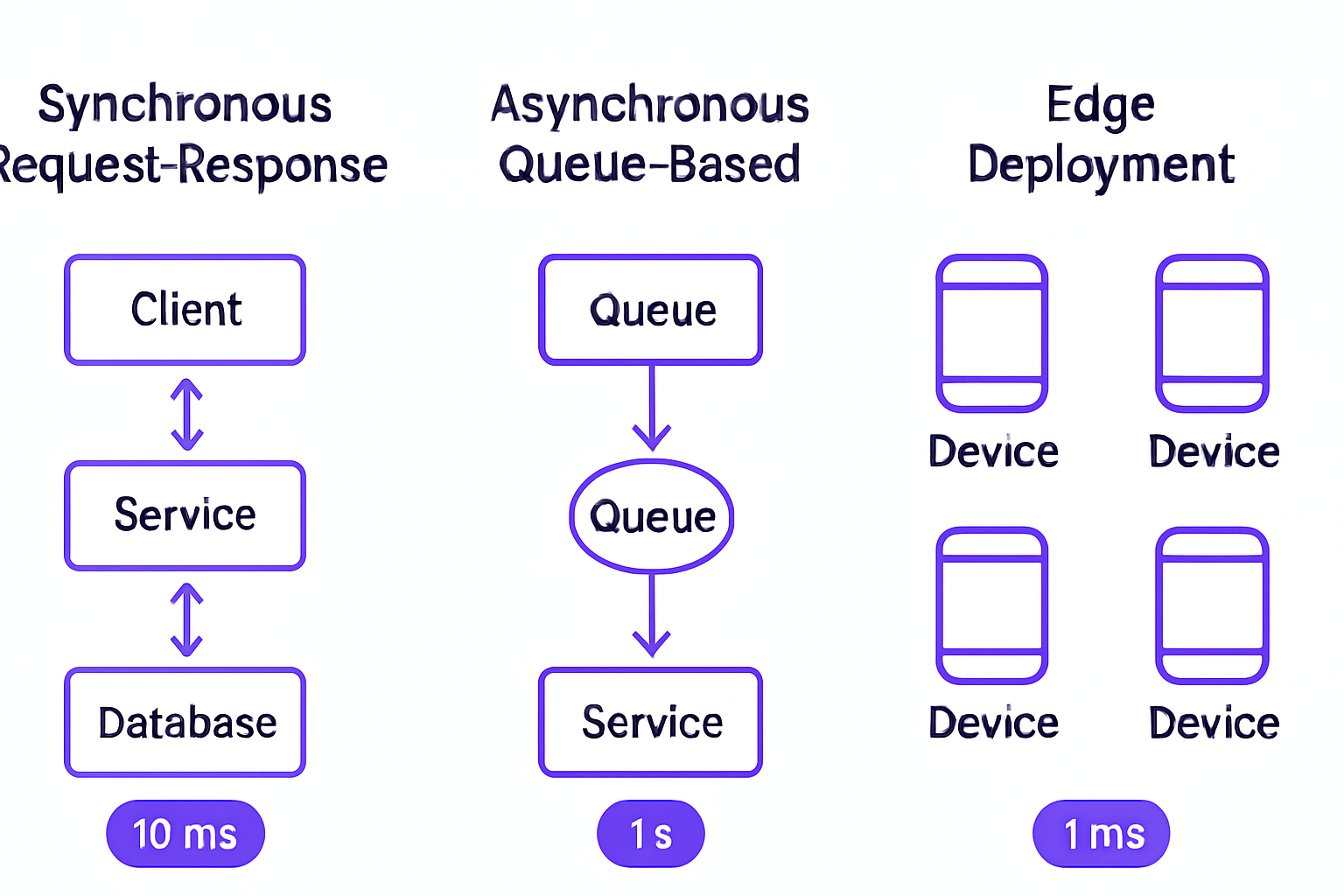
Batch vs. Real-Time
Daily churn predictions, inventory forecasts, and historical analysis belong in batch pipelines. Real-time inference belongs in user-facing decision flows: recommendations, fraud detection, dynamic pricing. Most mature production systems use both, separated cleanly.
Implementation Patterns That Scale
These six patterns move a deployment from "it works on my machine" to "it runs reliably under load."
Containerize Everything
Package your model and all its dependencies into a Docker image, tagged by model version. Push to a container registry. Deploy to Kubernetes or a serverless runtime. Reproducibility is the point. If you can't reproduce the exact environment that produced a prediction, you can't debug it.
Async Queues for Non-Blocking Predictions
If users don't need the answer immediately, don't make the API wait for it. Push the request to a queue (Redis, SQS, Celery) and process predictions in batches. This frees your API to keep responding and decouples inference throughput from request volume spikes.
Shadow Deployments
Run the new model alongside the old one, receiving the same traffic, without affecting users. Compare outputs side by side, measure latency differences, and build confidence in the new version before you ever route real traffic to it. This is one of the most underused patterns in ML engineering.
Canary Rollouts
Route 5% of traffic to the new model version. Monitor for 24 hours. Watch latency, error rates, and confidence distributions. If everything looks stable, ramp to 25%, then 100%. If something looks wrong, roll back before it hits the full user base.
Input Validation and Sanitization
Reject or log requests that fall outside your training distribution. This isn't just good hygiene. It's the difference between a model that fails silently on garbage inputs and one that surfaces the problem so you can address it. Garbage in, garbage out is still true in 2025.
Caching and Request Deduplication
If you see the same input twice within a short window, return the cached result. This cuts redundant compute, reduces inference costs, and improves perceived latency. It's a small change with a meaningful operational impact at scale.
Ready to Ship Your ML Model Safely?
Common Pitfalls and How to Avoid Them
Most production ML failures aren't caused by bad models. They're caused by predictable infrastructure mistakes that could have been caught earlier with the right monitoring.
Data Drift Without Detection
Your model trains on data from one period, then the world shifts. Feature distributions change. Target rates change. Your model's predictive power erodes quietly. You need continuous monitoring of input distributions, target rates, and prediction confidence scores. Without it, you're flying blind.
No Version Control for Data or Models
If you retrain a model and accuracy drops, you need to know exactly which training dataset, which preprocessing steps, and which hyperparameters produced the previous version. Git handles code. Tools like DVC and MLflow handle data and model versioning. Use both.
Forgetting the Latency Budget
Your model takes 500ms to predict. Your API timeout is 1 second. Network roundtrip adds 100ms. You're operating within a razor-thin margin, and any spike in inference time blows the budget. Profile end-to-end latency in production, not just on your local machine.
Single Point of Failure
One inference server should not be able to take down your product. Use load balancing, run multiple replicas, and plan for multi-region failover. The operational cost of this architecture is far lower than the business cost of an outage.
Training-Serving Skew
Your training pipeline computes features one way. Your serving pipeline computes them slightly differently. Predictions diverge from expectations without any obvious error. A shared feature store eliminates this problem. Without one, it's a recurring source of subtle, hard-to-diagnose bugs.
Ignoring Edge Cases
Your model was trained on images at 500x500 pixels. A user uploads something at 10000x10000. Or sends null values, extreme outliers, or deliberately adversarial inputs. Validate every input before it reaches the model. Have explicit fallbacks for inputs that fail validation.
How GroovyMark WebX Handles ML in Production
At GroovyMark WebX, we architect the entire inference layer, from model registry through serving, monitoring, and fallback logic. There are no black boxes in our delivery. You see exactly what's running, what version it is, and how it's performing.
Our Custom AI Agent Development service includes production-grade deployment, versioning, and observability built in from day one. We don't hand you a trained notebook and wish you luck. We design and ship the surrounding infrastructure that makes the model reliable under real-world conditions.
Every model we deploy is versioned. We track data drift, log predictions for audit trails, and build post-hoc analysis capabilities into the system. You own the data. We own the infrastructure that keeps it moving correctly.
"If something breaks, you should know before your customers do." That's the standard we build to at GroovyMark WebX. Real-time dashboards surface prediction latency, error rates, model confidence distributions, and drift alerts before they become product incidents.
We handle containerization, orchestration, scaling, and failover so your team can stay focused on what actually differentiates your product: feature engineering and model improvement. You can also see what we've built across fintech, eCommerce, logistics, and SaaS if you want to evaluate the work before starting a conversation.
If you've got workflow automation needs around your data pipelines, that sits naturally alongside ML deployment work and we handle both under the same engagement.
The team you talk to is the team that ships. No juniors, no handoffs. Every deployment comes with lifetime bug-free support and 24/7 coverage, because a model that fails at 2am on a Saturday is still your problem on Monday morning.
Talk to our team to walk through your ML deployment challenges. We've shipped predictive systems at scale and we're ready to build something reliable with you.
We Build Production-Grade ML Systems That Actually Work
Frequently asked questions
What's the difference between training and serving an ML model?
Training optimizes for accuracy on historical data — you run it once or quarterly. Serving optimizes for latency, throughput, and cost — it handles millions of predictions under load, with data that shifts and degrades over time. The architecture, monitoring, and failure modes are completely different. GroovyMark WebX builds the serving infrastructure so your model stays reliable in production.
How do I know if my model is decaying in production?
Monitor three things: prediction latency (is it getting slower?), error rates (are edge cases increasing?), and data drift (are input distributions changing?). Log predictions and ground truth when available; compare model outputs to recent data. GroovyMark WebX instruments every production system with real-time dashboards so you catch decay before it impacts users.
What happens if my inference service goes down?
Without a fallback, everything breaks. With one, you degrade gracefully: return cached predictions, use a simpler rule-based model, or queue the request for later. Load balancing and replicas prevent single-point failures. GroovyMark WebX designs fallback logic into every deployment so your product stays online even if your ML service doesn't.
How long does it take to deploy an ML model to production?
If you already have a trained model and infrastructure in place, 1–2 weeks. If you're starting from scratch, 4–8 weeks depending on complexity, data availability, and whether you need custom workflow automation around data pipelines. GroovyMark WebX typically delivers production-grade ML deployments on-time with our guarantee.
Should I use batch or real-time predictions?
Batch if the user doesn't need the answer immediately — daily reports, inventory forecasts, churn predictions. Real-time if they're waiting — product recommendations, fraud detection, pricing decisions. Most production systems use both. GroovyMark WebX architects the right mix for your use case and handles the integration end-to-end.


