
Microservices Architecture: Building Scalable Systems Without the Collapse
Microservices architecture promises independent deployments, team autonomy, and systems that scale without bringing everything down at once. But done wrong, it creates a distributed monolith that's harder to debug than the thing you replaced. This post covers the patterns that work, the mistakes that sink teams, and how to migrate safely.
The Microservices Trap: Why Distributed Systems Collapse
Microservices architecture fails most often not because the concept is wrong, but because teams split services before solving the harder problems: observability, fault isolation, and network resilience. When those are missing, you get all the operational overhead with none of the autonomy.
A monolith has one big advantage: when something breaks, you can trace it in a single process. Every function call is in-process. You can attach a debugger. You can read a stack trace. When you move to distributed services, that advantage disappears, and most teams don't replace it with anything.
Network calls replace in-process function calls. That single change introduces latency, partial failures, and timeout storms that simply don't exist in a monolith. A function that previously returned in microseconds now crosses a network boundary. When it's slow, the caller has to wait. When 100 callers are waiting, your upstream services queue up, memory fills, and the cascade begins.
The operational surface jumps sharply too. You now need container orchestration, service discovery, distributed tracing, centralized logging, and alerting per service. If your team hasn't invested in that infrastructure, you'll spend more time managing the system than shipping features.
Why Microservices Matter Now (And When They Don't)
Microservices architecture genuinely earns its overhead when team size and deployment complexity have made the monolith a bottleneck, not before. Below roughly 20 people, a well-designed monolith ships faster, costs less to operate, and is far easier to reason about.
O'Reilly's analysis of microservices adoption makes this point clearly: the operational cost of distributed systems only pays off when the coordination cost of a large engineering team working in a single codebase exceeds it. That crossover happens around 50 to 100 engineers, or when your domains have genuinely independent scaling profiles.
Sam Newman's canonical text, Building Microservices, frames service boundaries around business domains, not technical layers. Orders, Payments, and Shipping move at different speeds and have different scaling demands. Splitting along those lines gives teams true ownership. Splitting along technical layers (frontend service, database service, business logic service) usually creates a distributed monolith with extra steps.
The case for microservices is concrete: independent deployments mean a bug in the Payments service doesn't require a full system redeploy. Database per service means one team's schema migration doesn't lock every other team out of production. Polyglot engineering becomes a feature, not a liability. Each service can use the language and data store best suited to its job.
But if your team is under 20 people or your product has tightly coupled domain logic, splitting early will cost you. You'll spend months building infrastructure instead of features.
Distributed teams deploying microservices independently across time zones
Core Patterns That Make Microservices Work
The patterns that make microservices reliable aren't optional extras you layer on later. They're the foundation. Build without them and you're not doing microservices, you're doing a distributed monolith with a better commit history.
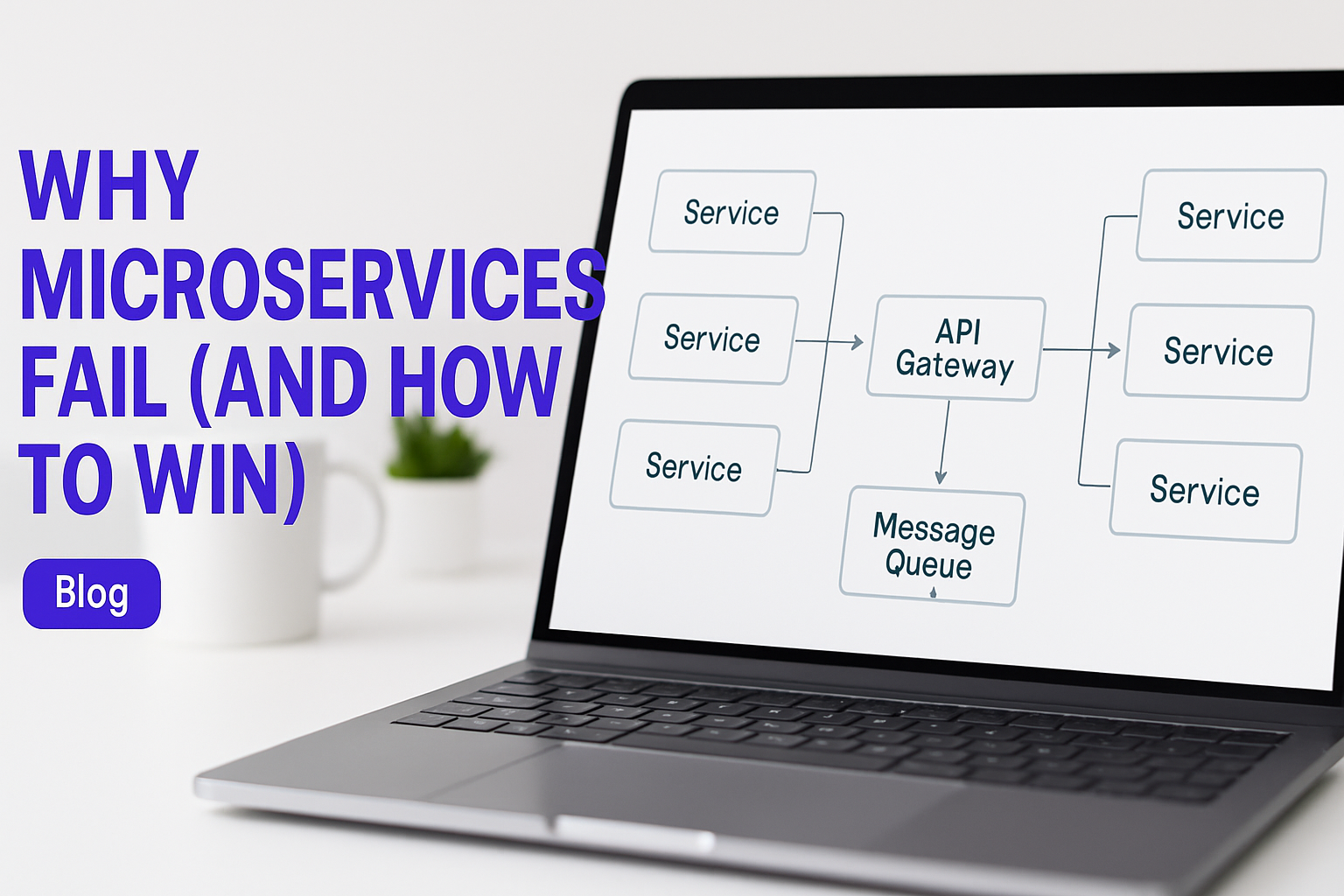
API Gateway
Every external client hits one entry point. The gateway handles routing, rate limiting, authentication, and protocol translation before traffic ever reaches a service. This keeps services thin and focused on their domain, not on cross-cutting concerns. Kong, AWS API Gateway, and Nginx are common choices depending on your deployment environment.
Service Discovery and Circuit Breakers
Services register themselves when they start and deregister when they stop. Clients query a registry (Consul, Kubernetes DNS) rather than hardcoding addresses. When you scale a service from 2 to 10 instances, clients find the new instances automatically.
Circuit breakers sit alongside service discovery as equally non-negotiable. The Google Cloud Architecture Center's reference patterns for distributed system resilience put the circuit breaker at the center of fault isolation strategy. A circuit breaker watches for errors and timeouts on calls to a downstream service. When the failure rate crosses a threshold, it opens the circuit, stops sending traffic, and lets the downstream service recover. Without it, one slow service drags everything upstream into timeout storms.
Event-Driven Communication
Synchronous RPC calls create coupling. If Service A calls Service B to complete an operation, Service A now depends on Service B's availability and response time. Event-driven communication breaks that dependency. Service A publishes an OrderPlaced event to a message broker (Kafka, RabbitMQ). Service B subscribes and processes it when it's ready. Neither service waits on the other.
This pattern also unlocks audit trails, replay, and fan-out: multiple services can react to the same event independently.
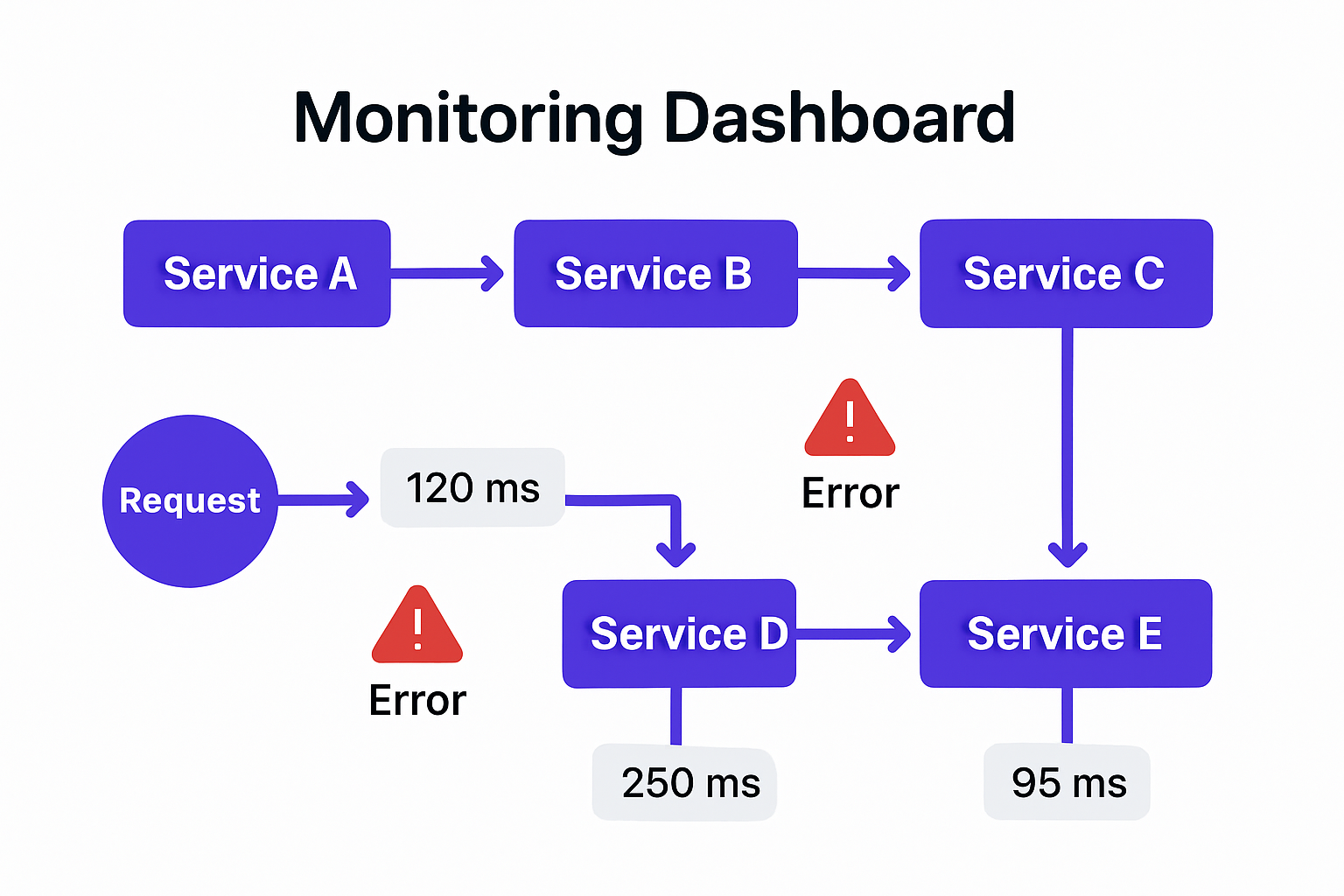
Distributed Tracing
Every request gets a trace ID generated at the gateway. That ID propagates through every service call in the chain. Your tracing system (Jaeger, Zipkin, Datadog APM) collects spans from each service and assembles them into a single view of the request. You can see exactly which service added latency, where an error originated, and how long each hop took.
Without this, debugging a user-facing timeout in a system with 10 services is guesswork.
Legacy and modern systems unified through microservices integration
Implementation Patterns: From Monolith to Microservices
Moving from a monolith to microservices without downtime requires a migration strategy, not a big-bang rewrite. Most teams that attempt a full rewrite end up with two broken systems instead of one.
The Strangler Fig Pattern
You incrementally replace monolith functionality by routing specific requests through a new microservice while the monolith continues handling everything else. An adapter layer (a reverse proxy or facade) sits in front of both systems and routes based on which endpoints have been migrated. The old system shrinks as the new services take over. Zero downtime, no flag day.
This is the default migration strategy we use when teams have existing systems that can't go offline. It's slower than a rewrite, but it's recoverable when something goes wrong.
Domain-Driven Design for Service Boundaries
If you draw your service boundaries around business domains rather than technical layers, your services will naturally align with the teams that own them. Conway's Law predicts this: your system architecture will mirror your org chart. Work with it, not against it.
Identify bounded contexts first. What data does each domain own exclusively? What are the domain events it produces? The answers to those questions define your service boundaries better than any technology framework.
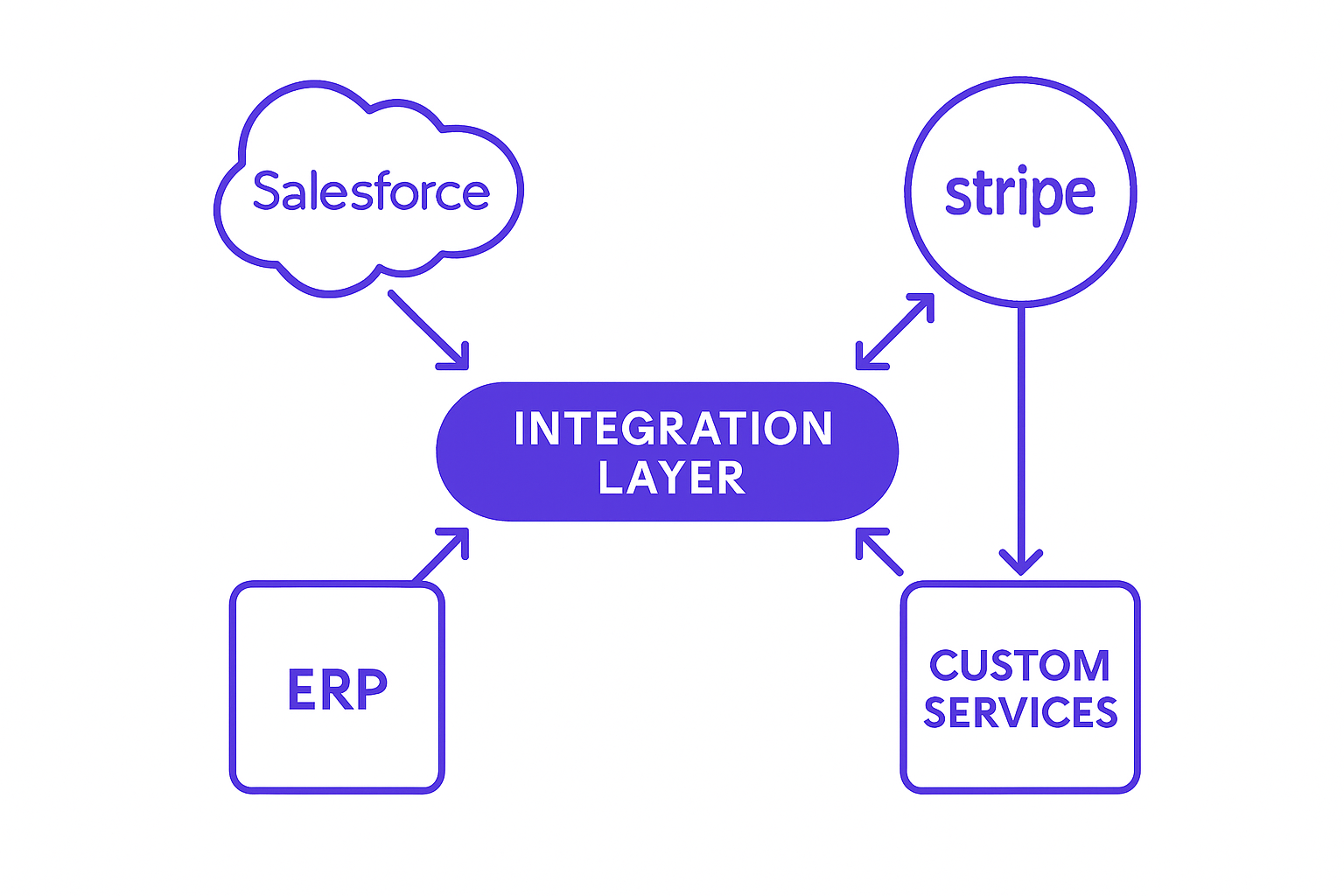
Legacy Integration: The Part Most Teams Skip
Existing ERPs, legacy databases, and proprietary systems don't vanish when you start building microservices. They have to coexist, and that coexistence needs an explicit design. Wrapping legacy systems in API adapters and event translators lets new microservices call them over standard interfaces without tight coupling to their internal schema.
ERP & Legacy System Integration is often where the real complexity lives. A new Orders service might need to read inventory from a 15-year-old ERP. A new Billing service might write to a legacy accounting system that has no API. Building those adapter layers correctly, with proper error handling, retries, and data validation, is frequently the hardest part of a microservices migration.
Not Sure If Your System Needs Microservices?
Common Pitfalls That Sink Microservices Teams
Most microservices failures are predictable. The patterns are consistent enough that you can look at an architecture diagram and spot the collapse before it happens.
The Distributed Monolith
Services call each other synchronously in long chains. Service A calls B calls C calls D. Every operation requires all four services to be up and responsive. One slow service stalls the entire chain. You've paid the operational overhead of microservices without gaining any of the fault isolation. Sam Newman identifies this as the most common microservices antipattern: distributed systems that have all the complexity of distribution and none of the independence.
Missing Observability
You can't fix what you can't see. Centralized logging, distributed tracing, and per-service metrics aren't nice-to-haves. They're the instrumentation that makes distributed systems operable. Without them, a 500ms latency spike in one service becomes an hours-long debugging session involving every team.
Without distributed tracing, debugging a microservices failure is investigative archaeology. You're sifting through logs from 10 systems looking for a single root cause that could have been visible in 30 seconds.
Database Coupling
Services that share a database are not independently deployable. A schema migration by one team requires coordination with every other team reading or writing the same tables. One team's slow query can affect everyone's performance. Database per service is a hard boundary, not a suggestion. If enforcing it requires duplicating some data across services and using event-driven sync to keep it consistent, that's the correct trade-off.
Premature Splitting
Splitting services before you understand your actual scaling bottlenecks adds operational complexity without solving the real problem. If your monolith is slow because of inefficient database queries, splitting it into microservices doesn't fix the queries. It just distributes them. Profile first. Split second.
How GroovyMark WebX Helps You Scale Without Chaos
The right architecture decision depends on where your team is today, not on what scales in theory. GroovyMark WebX starts every engagement with an architecture audit, because the answer might be microservices, or it might be a well-redesigned monolith that ships in half the time.
If you have existing monoliths, ERPs, or proprietary systems that need to stay in place, we build the API layers and event adapters that let them participate in a modern architecture without requiring a full rewrite. If you're a smaller team where some degree of coupling is fine for now, we build something lean that can be split later with clear domain boundaries already in place.
For teams ready to go distributed, GroovyMark WebX ships with observability and circuit breakers built in from day one, not added later when things go wrong. We instrument distributed tracing, configure centralized logging, and wire circuit breakers into every downstream call before a single request hits production.
We also handle the async-first design work that prevents cascading failures: message queues for background operations, event-driven communication between services, and dead-letter queues that catch failures without losing data.
Our Custom AI Agent Development capability means that when your microservices architecture is ready for intelligent automation, we can wire in agents that operate across your services, call APIs, process events, and take action without human intervention.
If you want to see how this works in practice, see how we've scaled systems for other teams. When you're ready to scope your own architecture, get in touch with our architecture team.
Distributed tracing dashboard visualizing request flow and performance across microservices
This work requires senior engineers who've shipped distributed systems at scale. At GroovyMark WebX, that's the baseline, not the exception. Every project gets that level of experience from the first conversation.
If your current architecture is showing cracks, or you're about to start building and want to get the structure right from the beginning, the time to address it is before the cascade, not after.
Ready to Integrate Legacy Systems With New Architecture?
Frequently asked questions
When should we split our monolith into microservices?
When your team exceeds 50 people, your deployment cycle takes over 2 hours, or your scaling bottleneck is clearly in one logical domain (Payments, Shipping) that moves independently. If you're under 20 people or deployment takes minutes, a well-designed monolith is faster. GroovyMark WebX can audit your system and tell you whether microservices or monolith redesign gets you to your goal first.
How do we prevent cascading failures in a microservices system?
Three layers: (1) Circuit breakers that stop sending traffic to failing services; (2) Timeouts on all network calls — don't let slow services hang forever; (3) Async communication via message queues for non-blocking work. GroovyMark WebX builds these patterns in from the start, so your system stays up when one service gets slow.
Can we use microservices with our existing ERP or monolith?
Yes. We wrap legacy systems in APIs and event adapters so they coexist safely with new services. The Strangler Fig pattern lets you gradually replace monolith functions without rip-and-replace. If you have an ERP, CRM, or legacy database that needs to stay, GroovyMark WebX designs the integration so new services can call it and subscribe to its events without tight coupling.
What observability do we need for microservices?
Distributed tracing (track requests across all services), centralized logging (see what every service did), and metrics (latency, error rate per service). Without it, debugging is impossible — a user sees a timeout, but you don't know which of 10 services was slow. We instrument your system for observability from day one.
Is Kubernetes required for microservices?
No. Kubernetes orchestrates containerized services at scale, but it adds operational overhead. If you have 3–5 services, a managed platform (AWS ECS, Google Cloud Run) might be simpler. If you have 20+ services with auto-scaling demands, Kubernetes or similar is worth it. We'll help you choose based on your team's ops maturity, not hype.


